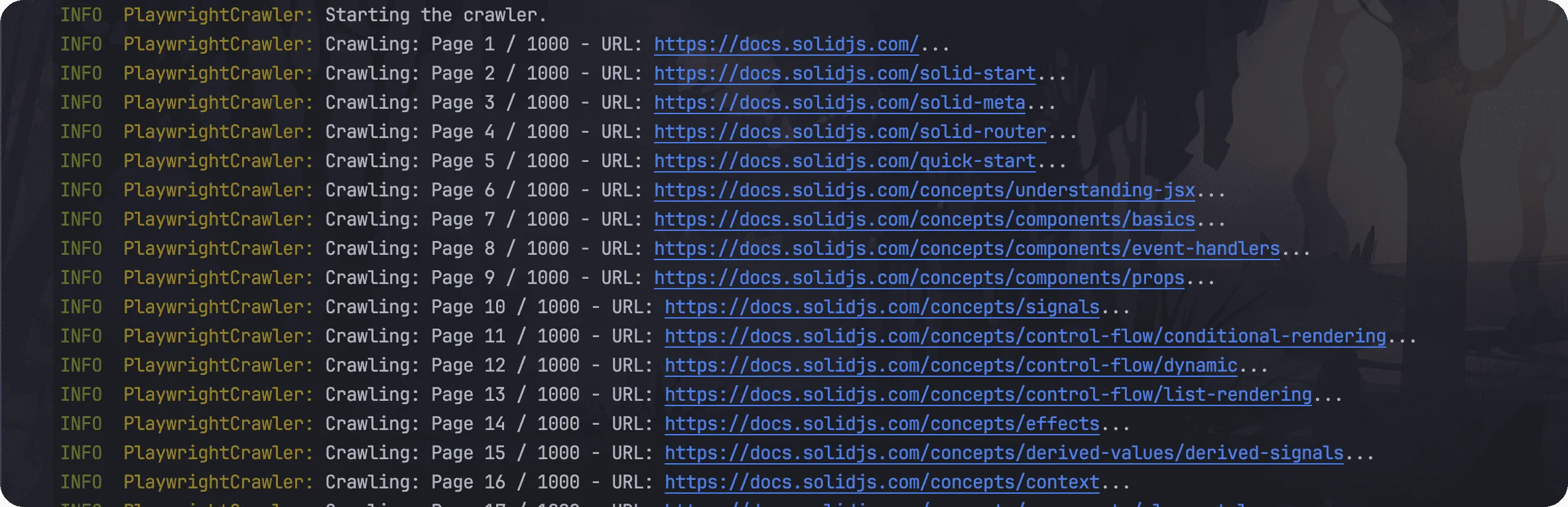
几条linux文本处理命令
Linux常用的文本处理命令
1. echo
基本用法: echo string
显示命令执行结果: echodate``
原样输出字符串,不进行转义或取变量(用单引号): echo '$name\\"'
启用转义符:echo -e "OK! \\c" # -e 开启转义 \\c 不换行
显示变量内容:echo "$name It is a test"
显示结果定向至文件:echo "It is a test" > myfile > 覆盖 >>追加
2. sort
sort 用于文本的行排序。默认排序方式是升序,按每行的字典序排序。
一些基本用法:
r降序(从大到小)排序u去除重复行o [file]指定输出文件n用于数值排序,否则“15”会排在“2”前
3. uniq
uniq 也可以用来排除重复的行,但是仅对连续的重复行生效。
通常会和 sort 一起使用:
1 | $ sort animals | uniq |
只是去重排序明明可以用 sort -u ,uniq 工具是否多余了呢?实际上 uniq 还有其他用途。
uniq -d 可以用于仅输出重复行:
1 | $ sort animals | uniq -d |
uniq -c 可以用于统计各行重复次数:
1 | $ sort animals | uniq -c |
4. grep
grep 全称 Global Regular Expression Print,是一个强大的文本搜索工具,可以在一个或多个文件中搜索指定 pattern 并显示相关行。
grep 默认使用 BRE,要使用 ERE 可以使用 grep -E 或 egrep。
命令格式:grep [option] pattern file
一些用法:
n:显示匹配到内容的行号v:显示不被匹配到的行i:忽略字符大小写o: 只返回匹配内容
1 | $ ls /bin | grep -n "^man$" # 搜索内容仅含 man 的行,并且显示行号 |
5. sed
sed 全称 Stream EDitor,即流编辑器,可以方便地对文件的内容进行逐行处理。
sed 默认使用 BRE,要使用 ERE 可以 sed -E。
命令格式:
1 | $ sed [OPTIONS] 'command' file(s) |
此处的 command 和 scriptfile 中的命令均指的是 sed 命令。
常见 sed 命令:
- s 替换
- d 删除
- c 选定行改成新文本
- a 当前行下插入文本
- i 当前行上插入文本
1 | $ echo -e "seD\\nIS\\ngOod" > sed_demo |
5. awk
awk 是一种用于处理文本的编程语言工具,名字来源于三个作者的首字母。相比 sed,awk 可以在逐行处理的基础上,针对列进行处理。默认的列分隔符号是空格,其他分隔符可以自行指定。
awk 使用 ERE。
命令格式:awk [options] 'pattern {action}' [file]
awk 逐行处理文本,对符合的 patthern 执行 action。需要注意的是,awk 使用单引号时可以直接用 $,使用双引号则要用 \\$。
一些示例:
1 | docker rmi $(docker images | grep "none" | awk '{print $3}') |
示例中 $1,$2,$3 分别指代本行的第 1、2、3 列。特别地,$0 指代本行。
awk 语言是「图灵完全」的,这意味着理论上它可以做到和其他语言一样的事情。这里我们不仅可以对每行进行操作,还可以定义变量,将前面处理的状态保存下来,以下是一个求和的例子:
1 | $ awk 'BEGIN { sum = 0 } { sum += $2 * $3 } END { print sum }' awk_demo |
6. *2>&1的含义*
关于输入/输出重定向本文就不细说了,不懂的可以参考这里:Shell:管道与重定向
- 含义:将标准错误输出重定向到标准输出
- 符号>&是一个整体,不可分开,分开后就不是上述含义了。
- 比如有些人可能会这么想:2是标准错误输入,1是标准输出,>是重定向符号,那么”将标准错误输出重定向到标准输出”是不是就应该写成”2>1”就行了?是这样吗?
- 如果是尝试过,你就知道2>1的写法其实是将标准错误输出重定向到名为”1”的文件里去了
- 写成2&>1也是不可以的
为什么2>&1要放在后面
考虑如下一条shell命令
1 | nohup java -jar app.jar >log 2>&1 & |
(最后一个&表示把条命令放到后台执行,不是本文重点,不懂的可以自行Google)
为什么2>&1一定要写到>log后面,才表示标准错误输出和标准输出都定向到log中?
我们不妨把1和2都理解是一个指针,然后来看上面的语句就是这样的:
1 | 本来1----->屏幕 (1指向屏幕) |
每次都写”>log 2>&1”太麻烦,能简写吗?
有以下两种简写方式
1 | &>log |
比如上面小节中的写法就可以简写为:
1 | nohup java -jar app.jar &>log & |
上面两种方式都和”>log 2>&1”一个语义。
那么 上面两种方式中&>和>&有区别吗?
语义上是没有任何区别的,但是第一中方式是最佳选择,一般使用第一种。
 wechat
wechat alipay
alipay