利用GPT-Crawler与ChatGPT构建个性化信息源
困境
面对专业性强的英文文档时,你是否也曾觉得难以理解,而向 ChatGPT 寻求帮助却发现其回答并不尽如人意?这不仅仅是因为 ChatGPT 的知识库可能已经过时,而且它的回答可能无法完全覆盖你的具体需求。例如,在查询如何使用 SolidJS 实现嵌套路由时,你可能发现 ChatGPT 提供的信息与官方文档不符。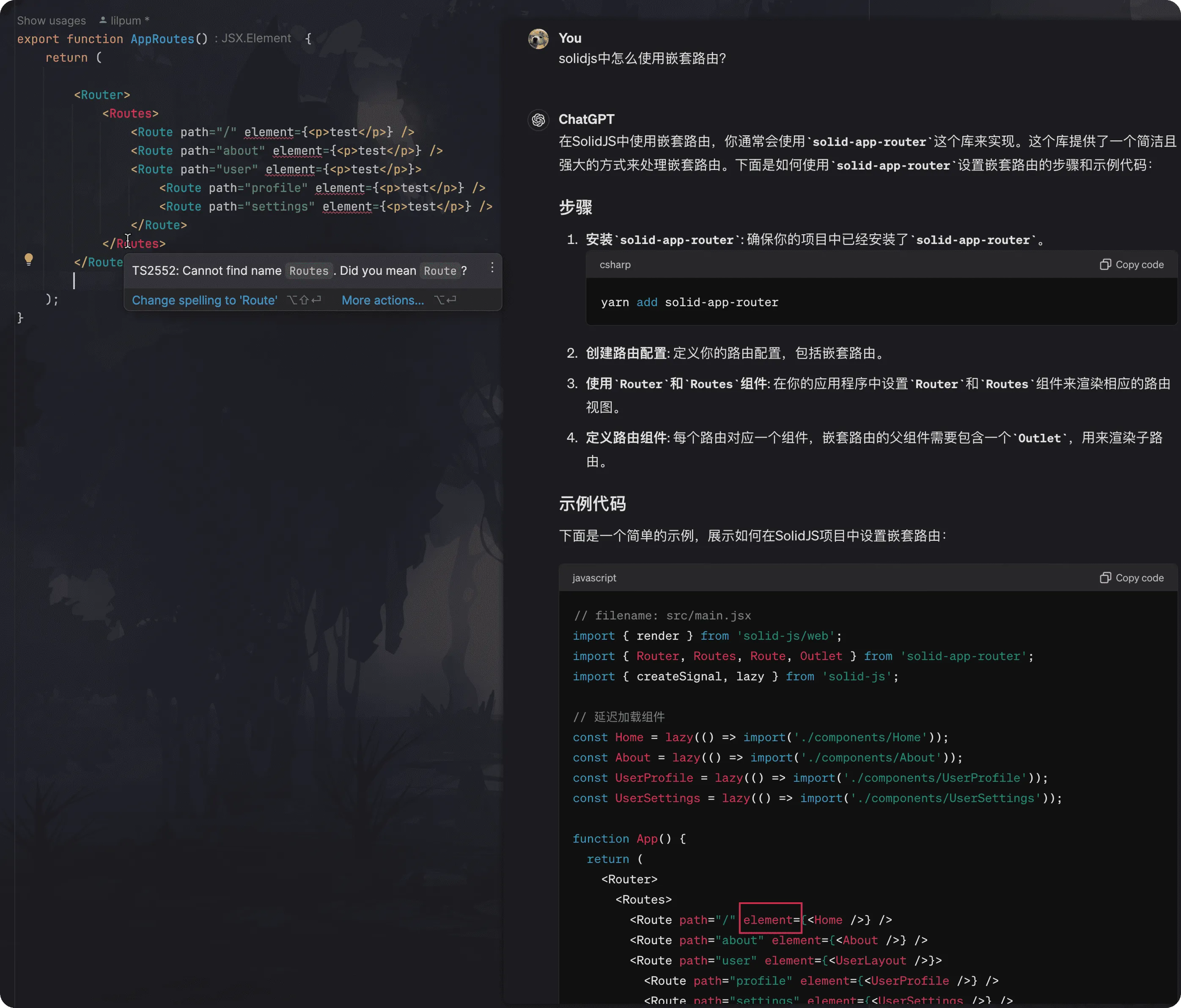
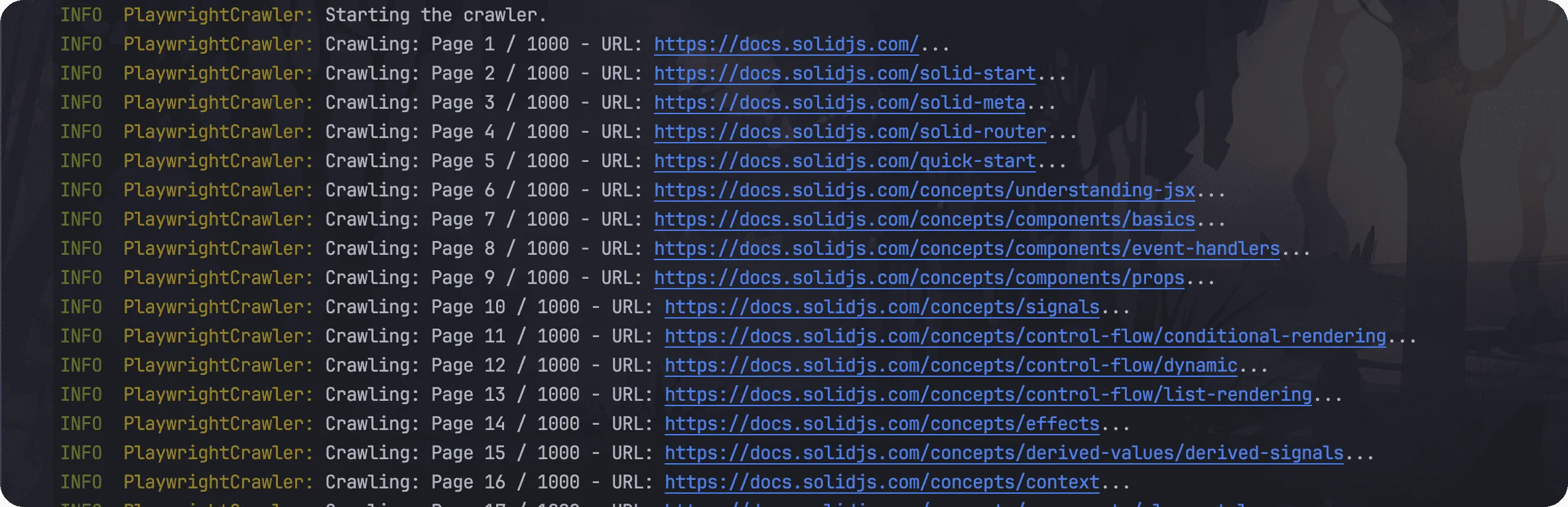
为了解决这一问题,我尝试使用 GPT-Crawler 来定制化 ChatGPT 的知识库。通过这种方式,不仅能提升 ChatGPT 的回答质量,还能确保信息的及时更新。
使用 GPT-Crawler 爬取 solidjs 官网文档的内容,并将其整合进 ChatGPT 后。很明显,ChatGPT 的回答更加准确更加接近官方文档。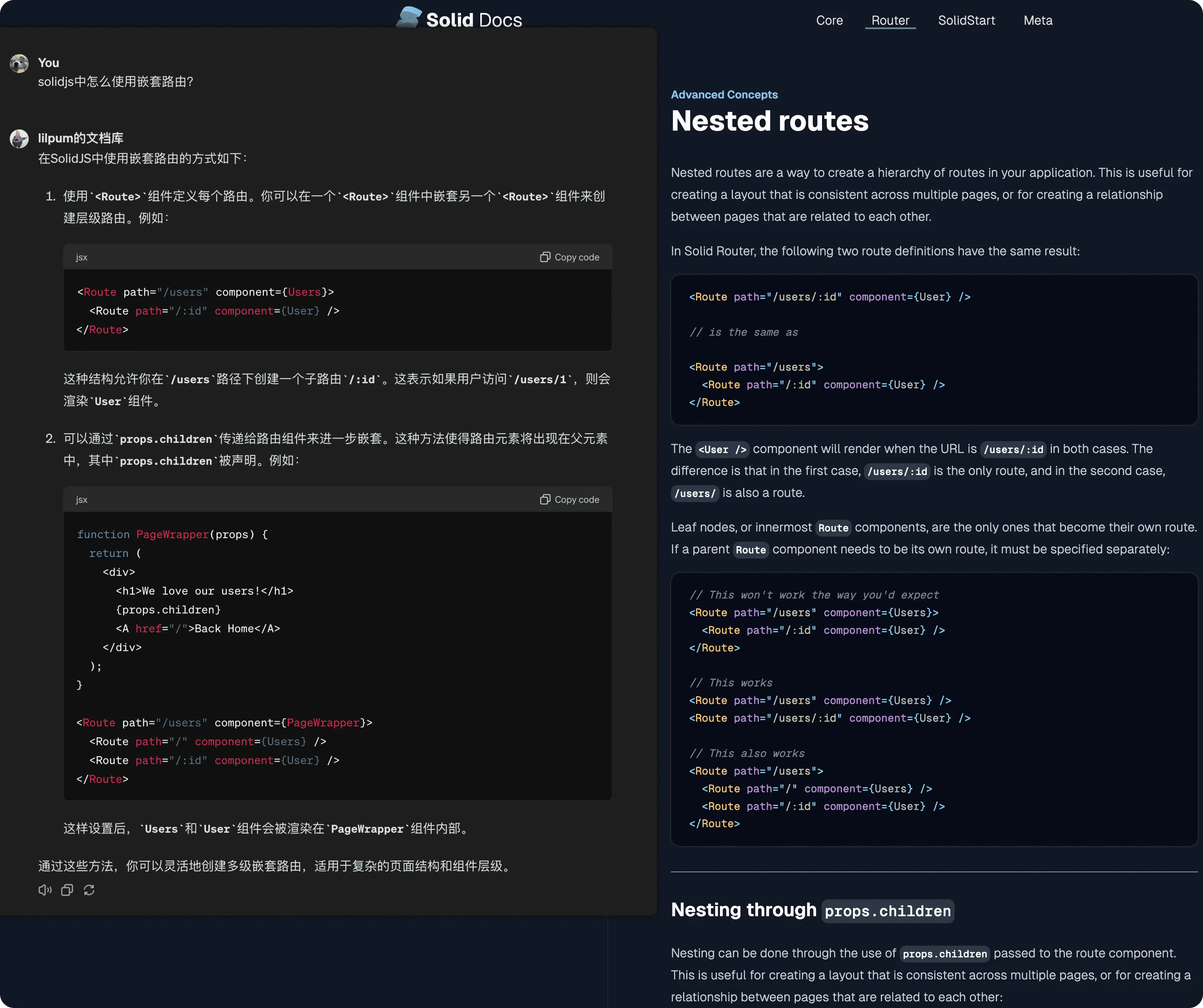
不是WebPilot用不了,而是全站扒下更靠谱!哈哈
GPT-Crawler 简介
GPT-Crawler 是一个开源项目,允许用户通过指定网站的 URL 爬取其内容,生成一个知识库文件,进而创建一个定制的 GPT 模型。这个项目通过一个简易的配置过程,允许用户指定开始爬取的网页、链接匹配模式、以及需要抓取的网页元素。使用这个工具可以帮助开发者快速创建基于特定主题或知识的自定义 GPT,增强AI模型的应用范围和效率。
使用方法
1. 安装GPT-Crawler项目
首先克隆项目到本地
1 | git clone https://github.com/BuilderIO/gpt-crawler.git |
然后进入到项目目录
1 | cd gpt-crawler |
安装依赖
1 | npm install |
2. 修改配置文件(配置需要抓取的内容)
打开 config.ts 文件,修改 url 和 selector 等属性以匹配你的需求。
1 | vim config.ts |
例如,要爬取 https://docs.solidjs.com/ 文档以制作我们的自定义 GPT,可以使用:
1 | export const defaultConfig: any = { |
selector 选择器
selector 是一个 CSS 选择器,用于指定需要抓取的网页元素。你可以使用浏览器的开发者工具来查看网页元素的选择器。
- 在浏览器中打开需要抓取的网页
- 右键点击需要抓取的内容,选择“检查”或“审查元素”
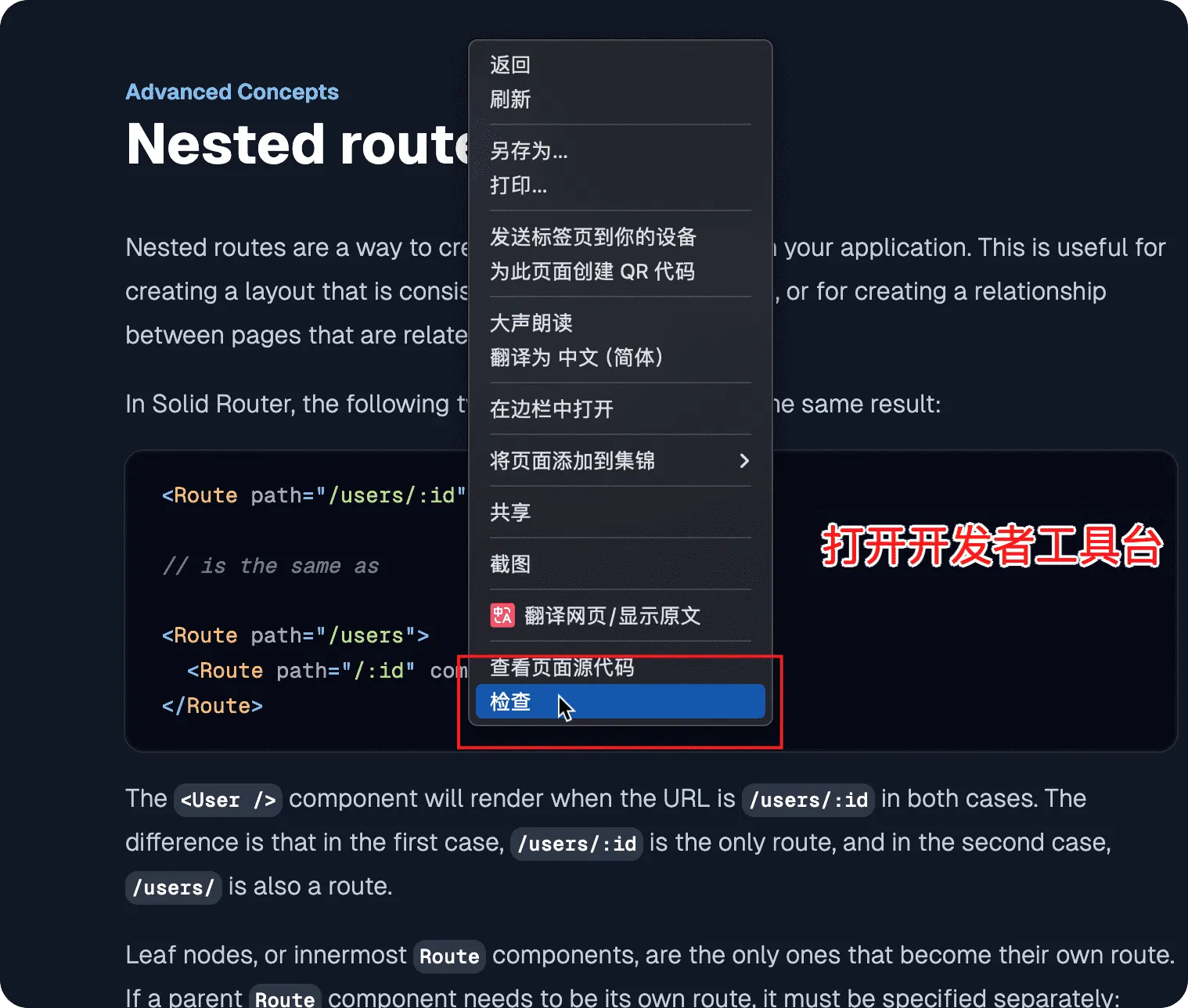
- 在开发者工具中右键点击需要抓取的元素,选择“Copy” -> “Copy selector”
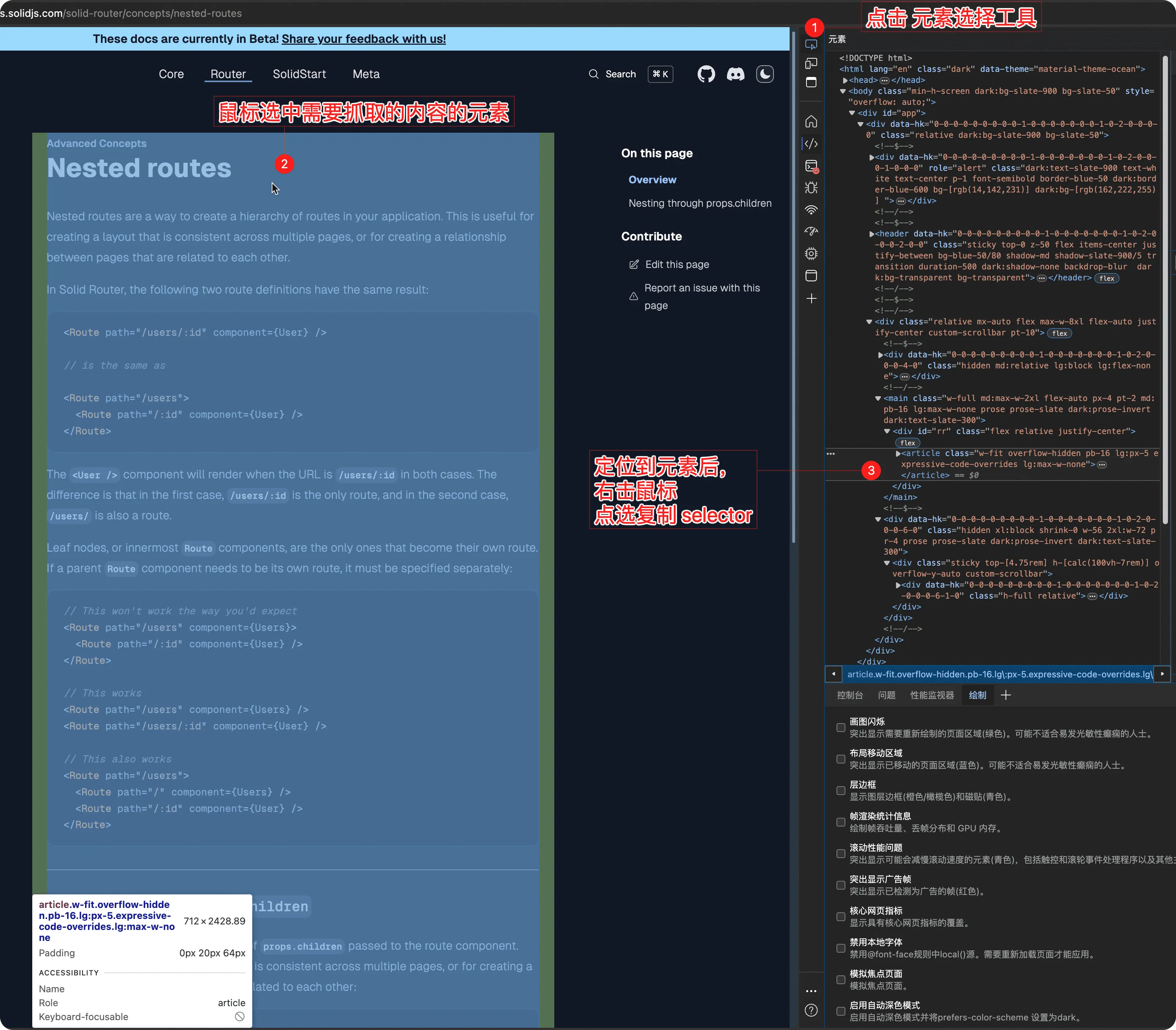
- 将复制的选择器粘贴到配置文件中的 selector 属性中
3. 运行爬虫
1 | npm start |
运行完毕之后,会在项目根目录生成一个 doc-solid.json 文件,里面包含了抓取的内容。
4. 制作自定义GPT
- chatgpt左侧菜单栏选择
Explore GPTs - 进入后点击右上角的绿色按钮
+ Create填写基本信息 name 和 description - 上传刚才生成的
doc-solid.json文件并设置 Instructions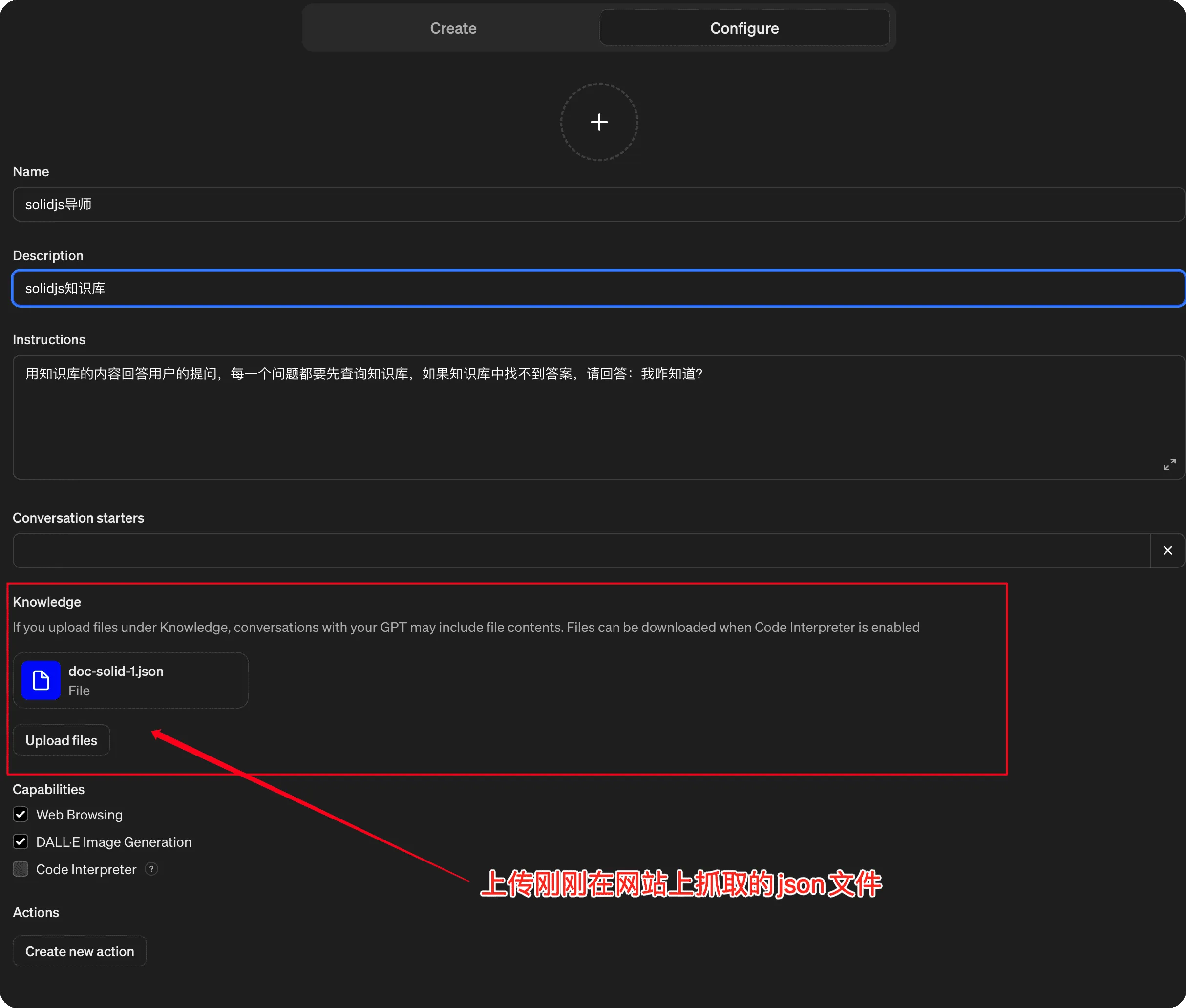
- 保存后即可直接使用。
- 在 chatgpt 中输入问题,即可得到更准确的回答。在其他窗口需要调用知识库时候可以直接使用@GPT名字来调用。
tips:是不是和gpt接口调用时候的functioncall(Agent)有点像?
 wechat
wechat alipay
alipay